Apache Cassandra is a highly scalable, distributed NoSQL database designed to handle large amounts of data across many servers, providing high availability with no single point of failure.
This practical guide will help you understand how to use Cassandra for real-world applications.
Table of Contents
Key Points
- Distributed and Decentralized: No single point of failure.
- NoSQL database
- Scalability: Horizontal scaling by adding more nodes.
- High Availability: Data is replicated across multiple nodes.
- Fault Tolerance: Can withstand node failures.
- Tunable Consistency: Allows you to choose the consistency level.
- Open Source database handled by Apache
Key Concepts in Cassandra
Login in console
cqlsh -u <username> -p <password>Keyspace
A keyspace is an outermost container for data in Cassandra, similar to a database in relational databases. It defines how data is replicated on nodes.
Attributes:
name: Keyspace name.replication: Defines the replication strategy and factor.durable_writes: Ensures data is written to disk.
Replication Strategies:
- SimpleStrategy: Used for a single data centre.
- NetworkTopologyStrategy: Used for multiple data centres.
Creating a Keyspace:
CREATE KEYSPACE my_keyspace WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };Using a Keyspace:
USE my_keyspace;List all keyspace:
DESCRIBE KEYSPACES;
Table
A table in Cassandra is a collection of rows. A unique primary key identifies each row.
Attributes:
name: Table name.columns: Columns in the table.primary key: Unique identifier for rows.
Creating a Table:
CREATE TABLE books (
id UUID PRIMARY KEY,
title TEXT,
author TEXT,
published_date DATE
);List All tables
DESCRIBE TABLES;Describing a Table:
DESCRIBE TABLE books;Data Types
Basic Types: text, int, uuid, boolean, timestamp, etc.
Collection Types: list, set, map.
Basic Operations
Insert
INSERT INTO users (user_id, name, email) VALUES (uuid(), 'John Doe', 'john.doe@example.com');Query Data
SELECT * FROM users WHERE user_id = <some-uuid>;Update data
UPDATE users SET email = 'john.new@example.com' WHERE user_id = <some-uuid>;Delete Data
DELETE FROM users WHERE user_id = <some-uuid>;Cassandra Architecture
Cassandra is a decentralized multi-node database that physically spans separate locations and uses replication and partitioning to scale reads and writes infinitely.
Decentralization
- Cassandra is decentralized because no node is superior to other nodes.
- No concept of master and slave nodes
- Every node acts in different roles as needed without any central controller.
Cassandra’s decentralized property is what allows it to handle situations easily in case one node becomes unavailable or a new node is added.
Every Node Is a Coordinator
- Data is replicated to different nodes. If certain data is requested, a request can be processed from any node.
- This initial request receiver becomes the coordinator node for that request. If other nodes need to be checked to ensure consistency then the coordinator requests the required data from replica nodes.
The coordinator can calculate which node contains the data using a so-called consistent hashing algorithm.
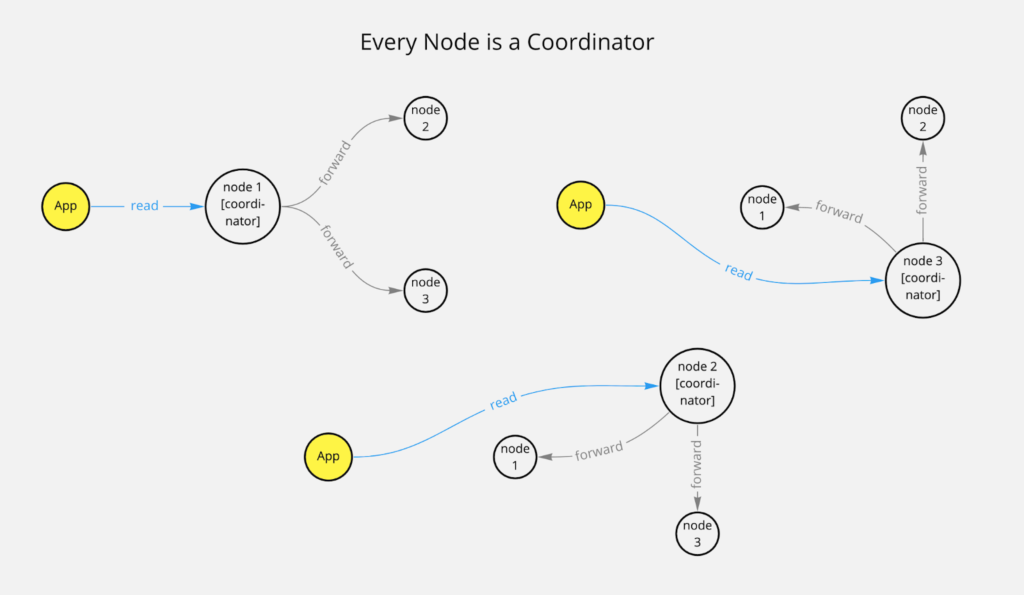
The coordinator is responsible for many things, such as request batching, repairing data, or retries for reads and writes.
Data Partitioning
- Partitioning is a method of splitting and storing a single logical dataset in multiple databases.
- By distributing the data among multiple machines, a cluster of database systems can store larger datasets and handle additional requests.
How Sharding Works by Jeeyoung Kim
As with many other databases, you store data in Cassandra in a predefined schema. You need to define a table with columns and types for each column.
Additionally, you need to think about the primary key of your table. A primary key is mandatory and ensures data is uniquely identifiable by one or multiple columns.
The concept of primary keys is more complex in Cassandra than in traditional databases like MySQL. In Cassandra, the primary key consists of 2 parts:
- a mandatory partition key and
- an optional set of clustering columns.
You will learn more about the partition key and clustering columns in the data modeling section.
For now, let’s focus on the partition key and its impact on data partitioning.
Consider the following table:
Table Users | Legend: p - Partition-Key, c - Clustering Column
country (p) | user_email (c) | first_name | last_name | age
----------------------------------------------------------------
US | john@email.com | John | Wick | 55
UK | peter@email.com | Peter | Clark | 65
UK | bob@email.com | Bob | Sandler | 23
UK | alice@email.com | Alice | Brown | 26 Together, the columns user_email and country make up the primary key.
The country column is the partition key (p). The CREATE-statement for the table looks like this:
cqlsh>
CREATE TABLE learn_cassandra.users_by_country (
country text,
user_email text,
first_name text,
last_name text,
age smallint,
PRIMARY KEY ((country), user_email)
);The first group of the primary key defines the partition key. All other elements of the primary key are clustering columns:
country --> partion key
user_email --> primary key(clustering columns)In the context of partitioning, the words partition and shard can be used interchangeably.
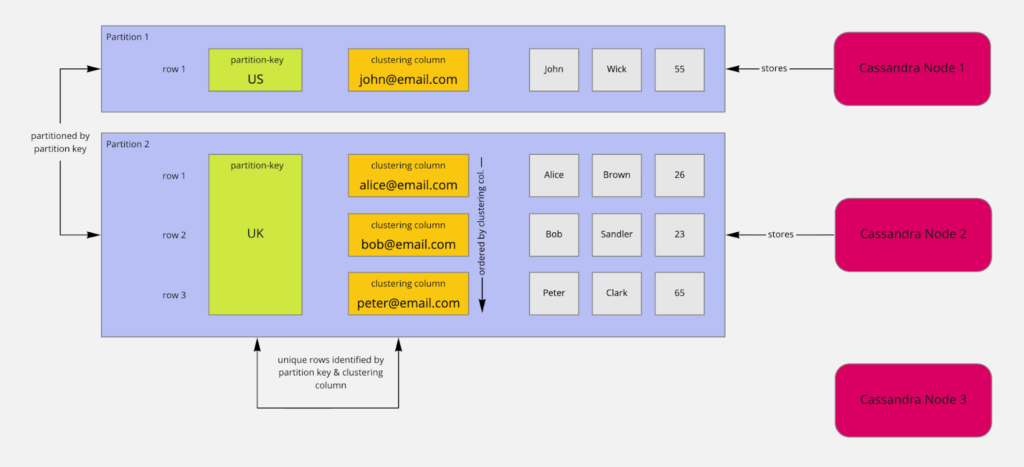
Partitions are created and filled based on partition key values. They are used to distribute data to different nodes. By distributing data to other nodes, you get scalability. You read and write data to and from different nodes by their partition key.
The distribution of data is a crucial point to understand when designing applications that store data based on partitions. It may take a while to get fully accustomed to this concept, especially if you are used to relational databases.
Consistency
Consistency levels in Apache Cassandra are a crucial concept that helps balance between availability and consistency in distributed systems. They determine how many nodes in the cluster must acknowledge a read or write operation before it is considered successful. This allows you to fine-tune the trade-off between strong consistency and high availability based on your application’s needs.
Consistency Levels in Cassandra
Overview
Consistency levels are configured for both read and write operations. They define the number of replica nodes that must respond for an operation to be successful. The choice of consistency level affects the latency, throughput, and fault tolerance of your Cassandra application.
Types of Consistency Levels
- ANY
- Write: A write operation is considered successful once any node (even if it’s a hinted handoff) acknowledges it.
- Read: Not applicable.
- Use Case: Maximum write availability but minimal consistency.
- ONE
- Write: Requires acknowledgement from at least one replica node.
- Read: Returns the value from the first replica node that responds.
- Use Case: Low-latency operations where strong consistency is not critical.
- TWO
- Write: Requires acknowledgement from at least two replica nodes.
- Read Returns the most recent data from two replicas.
- Use Case: Better consistency than ONE but still relatively low latency.
- THREE
- Write: Requires acknowledgement from at least three replica nodes.
- Read: Returns the most recent data from three replicas.
- Use Case: Higher consistency than TWO but at the cost of higher latency.
- QUORUM
- Write: Requires acknowledgement from a majority (quorum) of replica nodes.
- Read: Requires reading from a majority of replica nodes and returns the most recent data.
- Use Case: Balanced consistency and availability. Suitable for many production scenarios.
- Formula: (replication_factor / 2) + 1
- ALL
- Write: Requires acknowledgement from a majority of replica nodes in the local datacenter.
- Read: Reads from a majority of replica nodes in the local datacenter.
- Use Case: Multi-datacenter deployments where you want strong consistency within a data centre.
cqlsh> SELECT * FROM learn_cassandra.users_by_country WHERE country='US';In your cqlsh shell will send a request only to a single Cassandra node by default. This is called a consistency level of one, which enables excellent performance and scalability.
What does strong consistency mean?
In contrast to eventual consistency, strong consistency means only one state of your data can be observed at any time in any location.
For example, when consistency is critical, like in a banking domain, you want to be sure that everything is correct. You would rather accept a decrease in availability and increase of latency to ensure correctness.
Replication
Consider a lot of write requests arriving for a single partition. All requests would be sent to a single node with technical limitations such as CPU, memory, and bandwidth. Additionally, you want to handle read and write requests if this node is not available.
That is where the concept of replication comes in. By duplicating data to different nodes, so called replicas, you can serve more data simultaneously from other nodes to improve latency and throughput. It also enables your cluster to perform reads and writes in case a replica is not available.
A replication factor of one means there’s only one copy of each row in the cluster. If the node containing the row goes down, the row cannot be retrieved.
A replication factor of two means two copies of each row, where each copy is on a different node. All replicas are equally important; there is no primary or master replica.
As a general rule, the replication factor should not exceed the number of nodes in the cluster. However, you can increase the replication factor and then add the desired number of nodes later.
Usually, it’s recommended to use a replication factor of 3 for production use cases. It makes sure your data is very unlikely to get lost or become inaccessible because there are three copies available. Also, if data is not consistent between replicas at any point in time, you can ask what information state is held by the majority.
In your local cluster setup, the majority means 2 out of 3 replicas. This allows us to use some powerful query options that you will see in the next section.
Data Modeling
Key Concepts:
- Keyspace: Similar to a database in relational systems. It contains tables.
- Table: Collection of rows, similar to a table in relational systems.
- Partition Key: Determines which node stores the data.
- Clustering Columns: Defines the order of data within a partition.
Creating a Keyspace
CREATE KEYSPACE mykeyspace WITH replication = {
'class': 'SimpleStrategy',
'replication_factor': 3
};Creating Table:
USE mykeyspace;
CREATE TABLE users (
user_id UUID PRIMARY KEY,
name TEXT,
email TEXT
);Interesting Points
Why should you start with 3 nodes?
It’s recommended to have at least 3 nodes or more. One reason is, in case you need strong consistency, you need to get confirmed data from at least 2 nodes. Or if 1 node goes down, your cluster would still be available because the 2 remaining nodes are up and running.
Example
Case 1: With 1 node: If there is only one node, if it fails, the system can’t be repaired
case 2: with 2 nodes: If one of the nodes goes out of sync, then which node should be considered as truth
Case 3: with 3 nodes: if one node goes down, we get data from the other 2 nodes. In case you need strong consistency, you can confirm data from at least 2 nodes.
Understanding Bloom Filters in Cassandra
- Cassandra uses Bloom filters to speed up read operations. Instead of scanning each SSTable on disk for a requested row, the Bloom filter provides a quick way to determine if the row might be present in the table, thereby reducing the number of unnecessary disk reads.
- However, Bloom filters can produce false positives, meaning they might incorrectly suggest that a row exists, but they never produce false negatives, ensuring that existing data is never missed.
The Deletion Process in Cassandra
When data is deleted in Cassandra, it doesn’t immediately disappear from the SSTables on disk. Instead, Cassandra implements a two-phase deletion process:
- Logical Deletion with Tombstones: When a row or column is deleted, Cassandra creates a tombstone, which is a special marker indicating that the data has been logically deleted. The actual data remains in the SSTables, but the tombstone signals that it should be ignored during read operations.
- Retention of Tombstones: Tombstones are kept for a configurable retention period (by default, 10 days) to ensure that the deletion is propagated to all replicas across Cassandra’s distributed nodes. This guarantees consistency within the cluster before the data is physically removed.
- Compaction for Physical Removal: Periodically, Cassandra runs a process called compaction, which merges SSTables and removes tombstoned data that is no longer needed. During compaction, Cassandra permanently deletes the data and tombstones from the SSTables, reclaiming storage space and reducing read overhead.
How Deletions Affect Bloom Filters
Since a Bloom filter is a space-efficient structure that can only check for the existence of rows, it cannot support deletions directly. Once a row is inserted into the database, the Bloom filter is updated to reflect that the row might exist. However, when that row is later deleted (and a tombstone is created), the Bloom filter still indicates that the row might exist until the compaction process removes the tombstone and data from the SSTable.
This presents a challenge: Bloom filters cannot be updated to reflect deletions. Instead, they continue to function as if the deleted row still exists, meaning the Bloom filter may result in unnecessary reads due to false positives.
Managing False Positives in Bloom Filters After Deletions
Although Bloom filters may continue to indicate the presence of deleted rows, Cassandra mitigates this issue by using tombstones. Here’s how:
- Read Operations: When a read request is processed, Cassandra checks the Bloom filter to determine whether the requested row might be present in an SSTable. If the Bloom filter indicates a possible match, Cassandra then reads the SSTable. During the read, it checks for any tombstones associated with the requested row. If a tombstone is found, Cassandra knows that the row has been deleted, and it does not return the data, ensuring accurate results.
- Impact on Performance: While this system introduces some inefficiency (because SSTables might still be accessed even for deleted rows), it ensures that the database remains accurate. The occasional false positives caused by the Bloom filter are handled during the read by checking for tombstones.
Compaction and Bloom Filters
Cassandra’s compaction process plays a crucial role in maintaining efficient performance, particularly when it comes to Bloom filters:
- Compaction Overview: During compaction, Cassandra merges multiple SSTables into a smaller number of new SSTables. This process removes tombstones for data that has been deleted and whose tombstone retention period has expired. The merged SSTables are free from tombstoned data, and any new Bloom filters created during compaction no longer indicate the presence of deleted rows.
- Bloom Filter Refresh: After compaction, the new Bloom filters are built based on the new, compacted SSTables. Since the tombstoned data has been removed, the new Bloom filters are more accurate and reflect the true state of the data. This reduces false positives and improves read performance.
Conclusion
Apache Cassandra is a powerful database suited for applications requiring high availability and scalability. By understanding its setup, configuration, data modelling, and integration, you can leverage its capabilities to build robust, distributed systems. Remember to monitor your cluster, perform regular maintenance, and fine-tune performance settings to keep your Cassandra deployment running smoothly.
4 thoughts on “Practical Guide to Apache Cassandra”